What is AuditAgent?
Most AI tools can find security issues in smart contracts. Detection is largely a solved problem now. What sets AuditAgent apart is the rest. How fast it runs, how little noise it produces in production, and how honest we are about what it does not catch.
This page is the long version. If you only have ten seconds, the introduction is enough.
Which ecosystems we support
AuditAgent works on three ecosystems. EVM with Solidity, Starknet with Cairo, and Solana with Rust. The EVM ecosystem covers many EVM-compatible chains; the on-chain scan option lets you target a deployed contract on any of them. Pricing, scan limits, and the analysis pipeline are the same regardless of which ecosystem you scan.
How well does it work
The numbers below come from EVM evaluations. Starknet and Solana support is newer, and we will publish per-ecosystem numbers as that coverage matures.
EVMBench
On EVMBench, the OpenAI and Paradigm benchmark of 120 high-severity vulnerabilities across 40 audits, AuditAgent detected 80 and scored 67% recall. We ran every repository in the dataset with no skips. For the full per-model comparison (Claude Opus 4.6 at 47%, GPT-5.2 at 38%, and others), see AuditAgent on EVMBench.
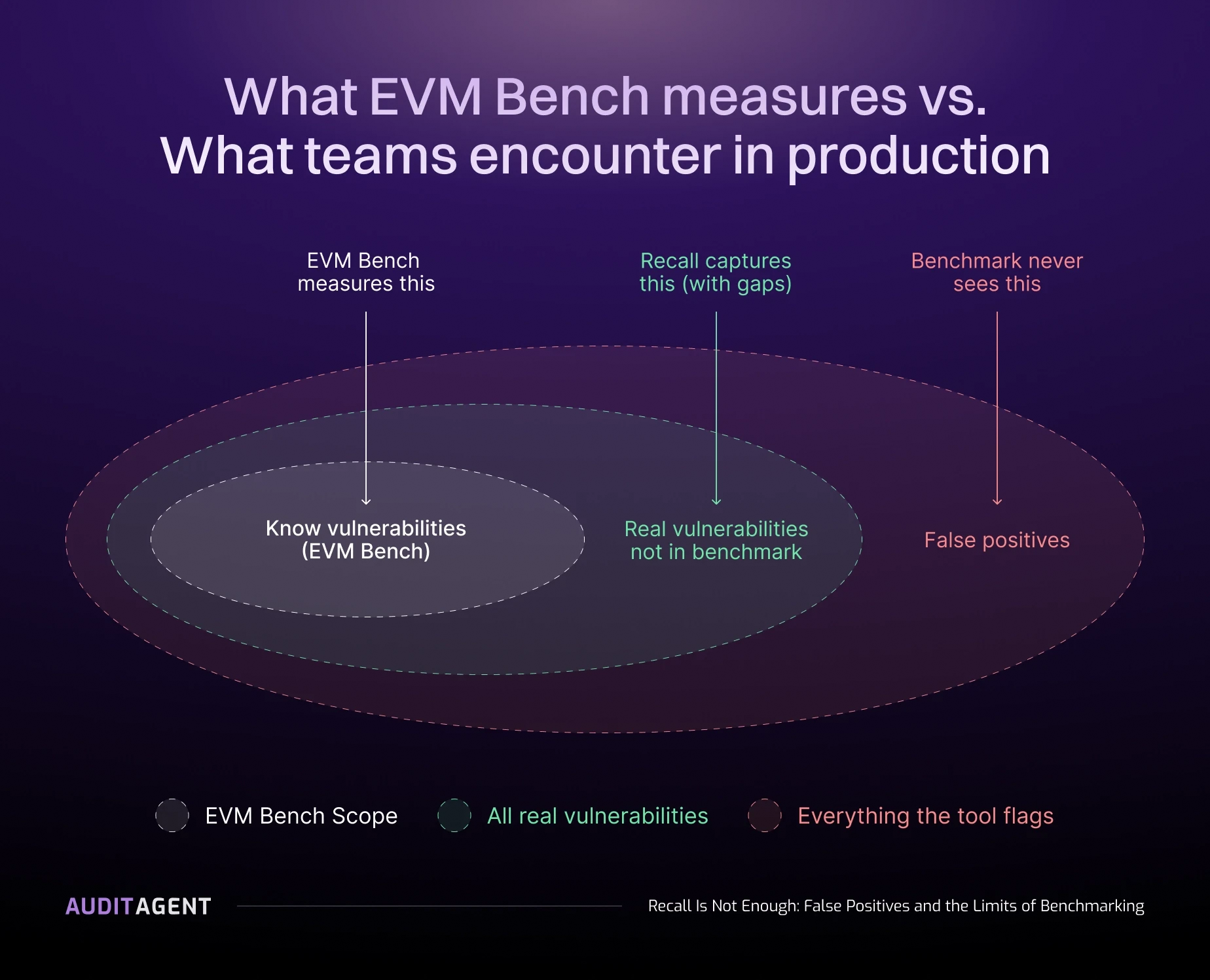
That 67% is the post-validation result. Pre-validation, AuditAgent's raw recall is 74%, but it also produces 3,230 findings instead of 798. The validation phase filters findings against a confidence threshold, trading 7 percentage points of recall for a 75% reduction in false positives. We publish the post-validation number because in production, teams pay for noise in triage time. EVMBench itself does not measure false positives or noise. See Recall Is Not Enough for the full argument.
Difficulty Benchmark
We also publish our own Difficulty Benchmark. It is built from 79 medium and high severity issues across 5 public audit competitions, split into "easier" and "harder" by the median number of independent auditors who reported each issue. The percentages you see on the scan selection screen are the fraction of each tier that our scans detect.
Nethermind Security usage
Nethermind Security is our own audit team. They run AuditAgent after manual review on engagements. Across 29 audited projects, the tool surfaced valid issues on 62% of them and matched 30% of human auditor findings. Critical-severity recall came in at 42% and high-severity at 43%. Read the full case study on the Nethermind blog.
ResupplyFi
After the June 27, 2025 ResupplyFi hack, in which $9.8M was lost to a miscalculation in exchange rate logic, we ran AuditAgent on the affected contracts on July 16, 2025. The tool flagged the exact issue.
CMTA and UBS
CMTA, the Swiss Capital Markets and Technology Association, and UBS used AuditAgent on the CMTAT v3.1.0 token standard, a Solidity framework for tokenised securities. AuditAgent scanned 75 contracts (5,999 lines of code) and surfaced 14 findings, complementing the team's existing Slither and Aderyn output. See the CMTA and UBS case study for the full methodology.
What you give the agent
You give the agent three things, in roughly this order of importance.
- Code. A repository, a branch, and the contract files you want analyzed. Up to 100 contracts and 12,000 BLoC per scan.
- Documentation. READMEs from the repo, public URLs, PDF/MD/MDX uploads, and free-form notes. The agent reads all of it.
- Clarifying answers. Optional answers to six structured prompts about deployment chains, trust assumptions, and design choices. See Additional Questions for the full list.
The richer the context you give, the more accurate the output. Documentation is not optional polish. It is how the agent disambiguates intent.
What you get back
When the scan completes, the dashboard surfaces five things.
- A severity-ranked list of findings. Each finding has a title, description, exploit path, and a code snippet.
- A code summary and an architecture diagram, generated from the contracts you submitted.
- A set of invariants the agent inferred. You can refine these and reuse them for fuzzing or formal verification.
- A security score on a 0 to 100 scale, weighted by severity, detector confidence, and code quality.
- An AI Chat interface per finding. You get 10 free chat credits per 500 BLoC for follow-up questions and remediation discussion.
You also receive an email with the audit report PDF attached as soon as the scan finishes, so you do not need to keep the dashboard open.
Persistent Memory
For projects you scan repeatedly, AuditAgent can hold a per-project knowledge base that captures architecture, invariants, hypotheses, contradictions, and excluded findings. Each subsequent scan builds on this accumulated context instead of starting from scratch, which reduces false positives and surfaces more meaningful findings.
Persistent Memory is available on Pro, Business, and Custom plans. See Persistent Memory for what it captures, how to initialise it, and how to review proposed updates.
Two scan tiers
The same pipeline runs at two compute budgets.
| Developer Scan | Auditor Scan | |
|---|---|---|
| Price | $0.02 per BLoC | $0.1 per BLoC |
| Compute | 1x | 5x |
| Scan time | Up to 1 hour | Up to 5 hours |
| AI models | Lightweight | Most expensive |
| Internet search | ❌ | ✅ |
| Multi-Agent System | ❌ | ✅ |
| Attacker Model | ❌ | ✅ |
The Auditor Scan adds three pipeline extras (Multi-Agent System, Attacker Model, and Internet Search) that give it materially higher recall on harder findings. See What runs during a scan for what each one does, or Scan Pricing for the full per-tier breakdown.
A pair auditor, not a replacement
We do not claim AuditAgent replaces a skilled human reviewer. The tool struggles with complex multi-contract, multi-call exploits where different state variables need to be tracked in depth across many transactions. It produces false positives that a human needs to filter, but should nonetheless be considered for the system integrity (checklist). Even with EVMBench's 67% recall, roughly a third of the known high-severity issues still get missed.
Think of AuditAgent as a pair auditor, a fast and structured second pass that catches what humans miss and frees the human to focus on the parts that need real judgement. Nethermind Security uses it exactly this way.
What AuditAgent does not catch
- Complex exploits that require deep familiarity with the protocol's economic model.
- Vulnerabilities outside the contract layer, such as frontends, deployment scripts, or off-chain infrastructure.
- Anything you exclude from scope at scan time.
LLMs hallucinate. Review every finding before you act on it.